БЕЗ скриптов, макросов, командной строки и регулярных выражений.
Эта статья понадобится студентам, каковые желают скачать все картины с сайта разом, дабы позже одним перемещением засунуть их в Power Point и сходу взять готовую презентацию. Обладателям электронных библиотек, каковые собирают новые книги по ресурсам соперников. Легко людям, каковые желают сохранить занимательный сайт/страницу в соцсети, опасаясь, что те смогут не так долго осталось ждать провалиться сквозь землю, и менеджерам, собирающим базы контактов для рассылок.
Имеется три главные цели извлечения/сохранения данных с сайта на собственный компьютер:
Дабы не пропали;
Дабы применять чужие картины, видео, музыку, книги в собственных проектах (от школьной презентации до полноценного сайта);
Дабы искать на сайте данные средствами Spotlight, в то время, когда Гугл не осилит (к примеру поиск изображений по exif-данным либо музыки по исполнителю).
Ситуации, в то время, когда нежданно пригодится автоматизированно сохранить какую-ту данные с сайта, смогут произойти с каждым и нужно быть к ним готовым. Если вы можете писать скрипты для работы с утилитами wget/curl, то имеете возможность смело закрывать эту статью. А вдруг нет, то на данный момент вы определите о самых несложных приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт полностью для просмотра оффлайн
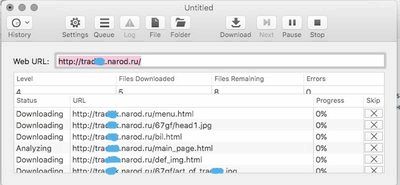
В OS X это возможно сделать посредством приложения SiteSucker. В App Store оно продается за 379 рублей, но на сайте возможно скачать ветхие версии приложения безвозмездно. В примерах использована версия 2.4.6, которой вполне достаточно для исполнения большинства задач. Пользователи Windows смогут применять HTTrack Website Copier, которая настраивается схожим образом. Continue reading







